Umi-OCR文字识别工具(离线识别不联网)

Umi-OCR文字识别工具(离线识别不联网)
laoyeeOCR 识别发展到现在精确度已经非常高了,各种网站吃相难看不让复制,有了 OCR 识别就可以一键提取出来了,对于一些软件内的文字说明也能通过此方式来复制文字
对于轻度使用的用户,其实微信截图就自带了,功能简单识别率也不错且方便好用,而且还没次数限制
以前分享过一款天若 OCR 也已经多年没更新,后续也有本地离线版流出,体验也一般般,这里就不推荐了,分享一款开源免费无广告的新工具 — Umi-OCR
纯本地识别处理,不用担心上传用户数据,方便识别一些私密的内容了
软件介绍
- 免费:本项目所有代码开源,完全免费
- 方便:解压即用,离线运行,无需网络
- 高效:自带高效率离线OCR引擎。只要电脑性能足够,可以比在线OCR服务更快
- 灵活:支持命令行、HTTP接口等多种调用方式
- 功能:截图OCR / 批量OCR / 二维码 / 数学公式识别
软件支持多国语言,第一次打开软件时,将会按照你的电脑的系统设置,自动切换语言
标签页形式展示跟浏览器体验差不多,可快速切换相应功能界面
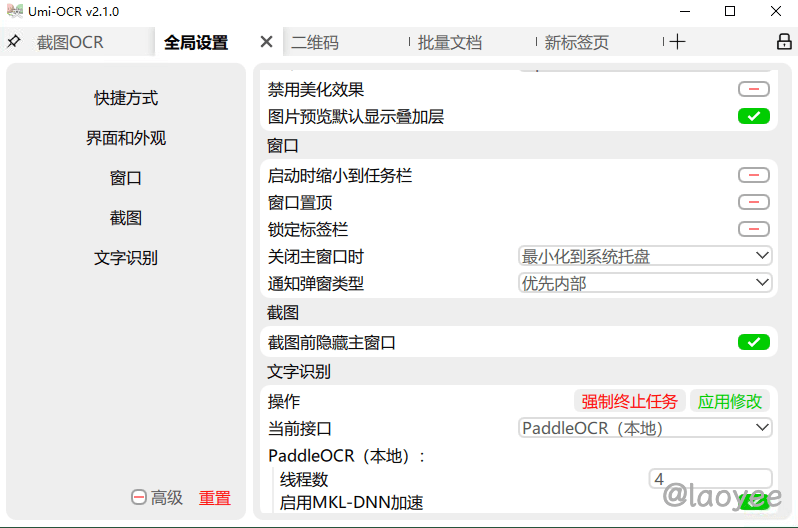
文字识别算是 Umi-OCR 最基础的功能了,设置好自定义快捷键后直接上手使用
识别后的文字段落排版还能自定义设置,更加方便内容提取
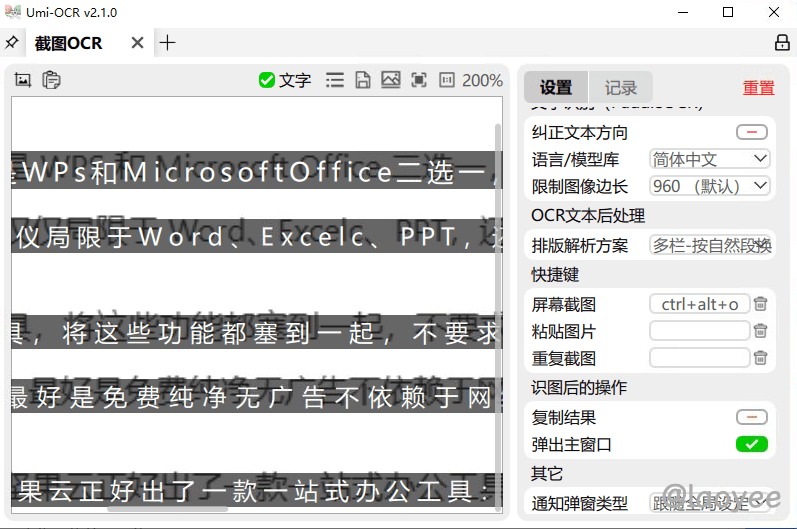
关于 OCR文本后处理 - 段落合并: 可以整理OCR结果的排版和顺序,使文本更适合阅读和使用。预设方案:
- 单行:合并同一行的文字,适合绝大部分情景。
- 多行-自然段:智能识别、合并属于同一段落的文字,适合绝大部分情景,如上图所示。
- 多行-代码段:尽可能还原原始排版的缩进与空格。适合识别代码片段,或需要保留空格的场景。
- 竖排:适合竖排排版。需要与同样支持竖排识别的模型库配合使用。
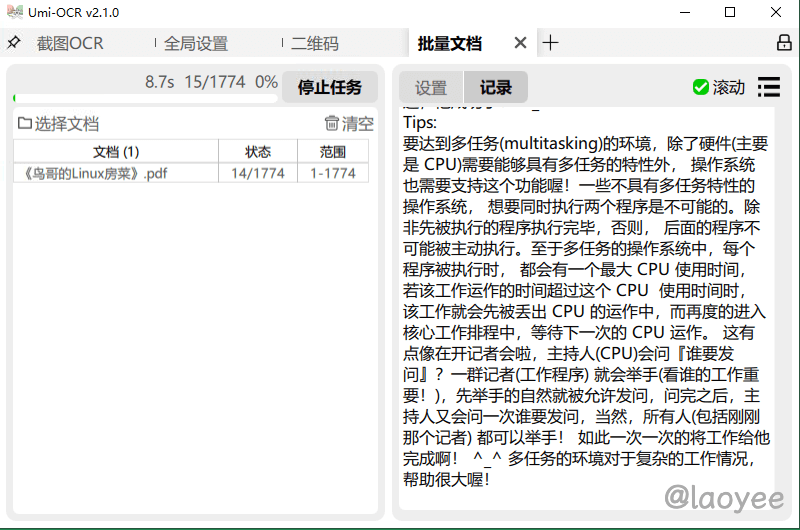
批量识别支持批量图片和批量文档,支持主流的文件格式
保存识别结果的支持格式:txt, jsonl, md, csv(Excel)
与截图OCR一样,支持文本后处理功能,整理OCR文本的排版和顺序。没有数量上限,可一次性导入几百张图片进行任务。
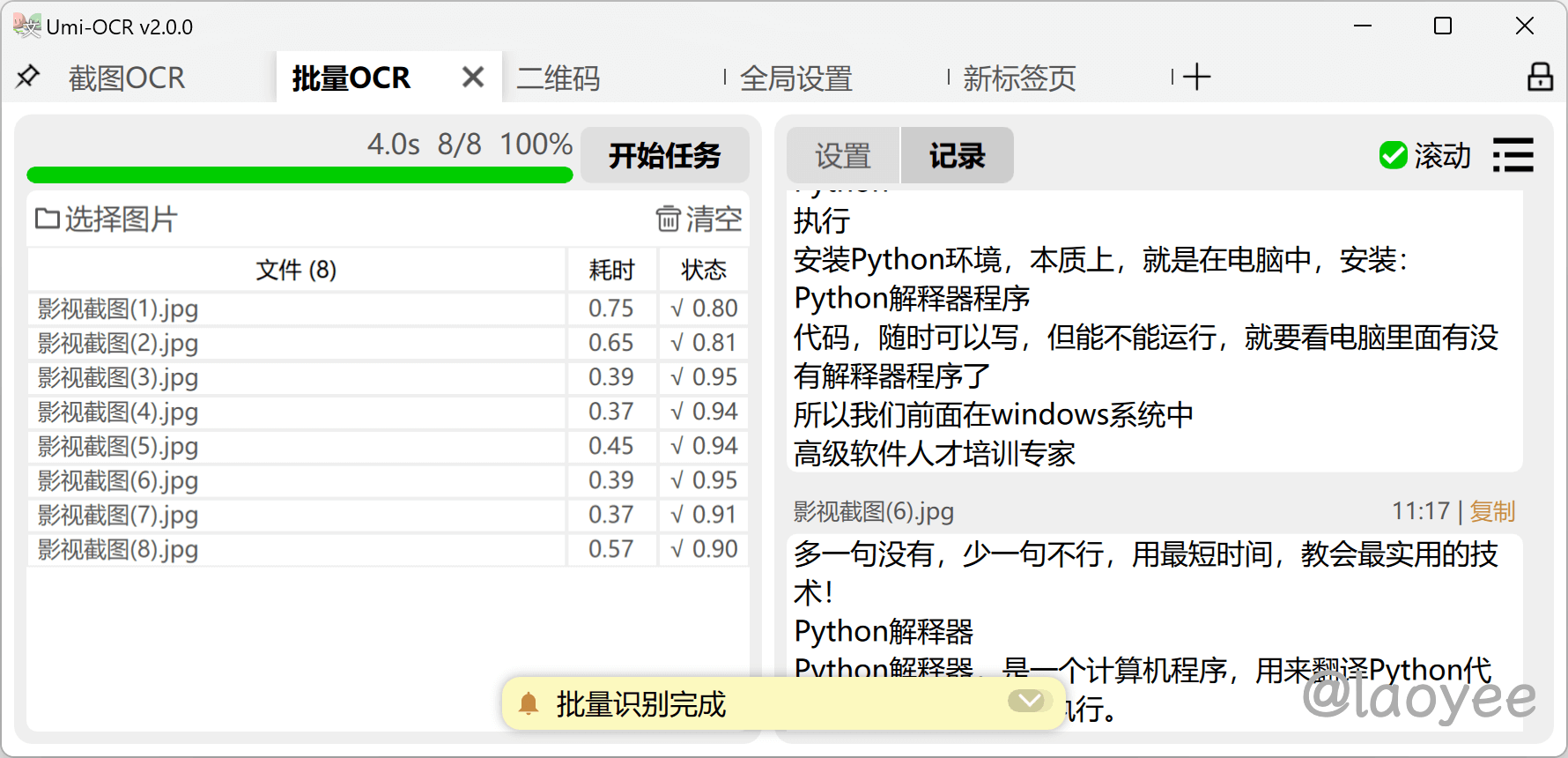
文档识别功能也是一大特色了,老夜尝试一个稍微大点的 PDF 文件也是丝毫没问题,软件没出现崩溃的情况
- 支持格式:
pdf, xps, epub, mobi, fb2, cbz - 对扫描件进行OCR,或提取原有文本。可输出为 双层可搜索PDF
- 支持设定 忽略区域 ,可用于排除页眉页脚的文字
- 可设置任务完成后 自动关机/休眠
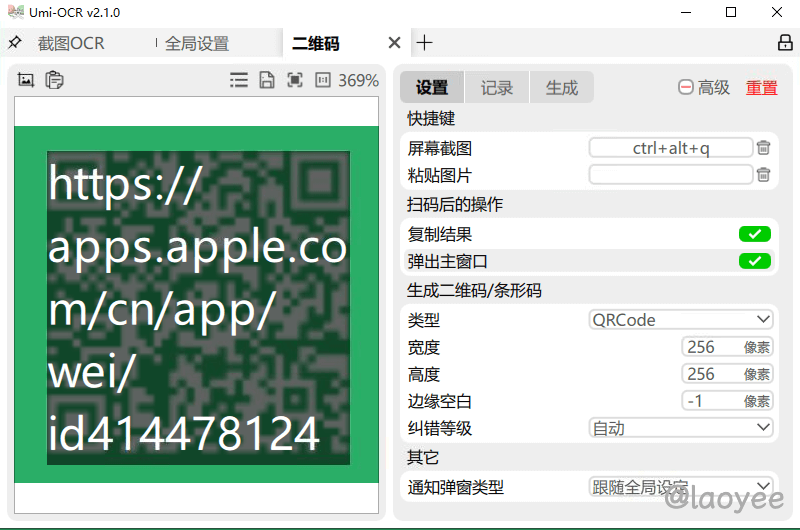
支持二维码识别,但是仅限于标准的二维码,对于那些美化过的码就无法识别
再补充一个二维码解码在线工具
资源获取



评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果









